在第三节中,已经向读者介绍了clickhouse在处理数据时按照block为单位进行压缩,之后写入磁盘数据文件中。这样可以减少数据量的大小减少磁盘io时间。但是,如果没有索引,则意味着每次查询时都需要读取所有的数据,即使通过压缩已经降低了6.2倍的数据量,这依然要花费很多的磁盘IO。此时索引就出现了,可以再次帮助我们减少查询时需要读取的数据量。
在介绍clickhouse的索引之前,我们先回顾一下关系型数据库MySQL中常用的索引技术——B+树。B+树算法超出本文内容,在这里不做深入讨论,我们主要分析下MySQL使用B+树的目的和B+树的本质。其实,B+树本质是一颗N叉树,其叶子节点就是有序排列的索引值,因此在查询时可以根据这棵树快速定位到数据所在,而且由于其有序,可以适应范围查找。下图展示了一颗B+树。
了解了B+树的本质之后,读者可以试着回答一个问题:clickhouse是否有必要使用B+树进行索引?为什么?
如果您的答案是不需要,那么说明您已经对clickhouse和MySQL存储引擎都了解地比较深入了。如果您的答案是需要或者不确定,那么也不用着急,下面就会详细说明原因。
这个问题的答案就是不需要,原因在于clickhouse的存储引擎和MySQL的存储引擎设计上的不同。MySQL由于要支持事务,使用MVCC的事务控制机制,因此会出现一个问题:数据的插入顺序和索引的排序不同。例如我对age列做索引,我的插入顺序为44,21,20,33,19。这组数据在B+树中需要被重新排列为19,20,21,33,44。这就是数据的插入顺序和索引排序不同的情况。而在关系型数据库中数据的插入顺序就是存储引擎写入数据文件的顺序。
在clickhouse的存储引擎中,在第三章和番外篇中已经详细介绍了LSM机制,clickhouse的存储引擎通过LSM机制保证数据的按照主键的顺序写入存储引擎,也就是说即使插入顺序为44,21,20,33,19。这组数据在经过clickhouse的LSM机制后写入数据文件的顺序就是19,20,21,33,44。这意味着clickhouse在存储数据时已经有序存储了,因此不需要再次使用 B+树进行索引了。
一级索引
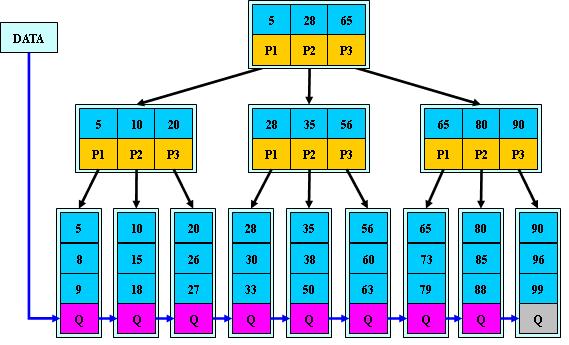
综上,其实clickhouse的一级索引非常简单,只需要记录每一个block第一个值即可。例如一组一亿行的数据,主键范围从1~100,000,000。存储到clickhouse后按照8192行为一个block,那么一共有12208个block。索引为1,8193,16635……在查询时只需要就可以根据值确定到需要读取哪几个block了。例如我需要查询id>500 and id <12258的数据,那就只需要读取第0块和第1块block即可。
在clickhouse的数据存储文件中,一级索引存在于primary.idx中。一级索引的本质是存储了每个block中数据的最小值,从而为确定需要查询的数据确定好其所在的block。它简历了数据到block的映射关系。简单来说,给定一个数据,通过一级索引能够快速查询到这个数据所在的block。从而避免查询一个数据需要遍历整个数据集。
标记
上面一部分已经给读者介绍了什么是一级索引。但一级索引并不能单独实现快速查找的目标。或者说,一级索引只实现了数据到block的映射。但还存在一个问题,我即使已经知道我的数据存储在了第一个block,那我如何定位到这个block的位置呢?这个问题的答案就需要通过标记文件来实现。换句话说,标记文件存储了block到文件偏移量的映射。
这个问题其实也不难理解,我们知道一个block是8192行数据组成的。如果每个block的大小都是64M。那么找到第N个block的地址就很容易,通过N*64m即可,但关键block经过压缩后是无法保证其大小的,也就是说每个block的大小是不同的。那么就必须将每个block的起始位置存储下来,方便查找。
在clickhouse的实际处理中,每行标记有3个字段组成blockid,数据文件中的偏移量,压缩后块中偏移量。每个字段是8字节,因此每个标记一共24字节。通过blockid可以N*24B快速定位到位置。
其实有blockid和数据文件中偏移量,就已经可以快读定位了,那么clickhouse标记文件中的第三项压缩后块中偏移量是用来做说明的呢?这个问题的答案其实和clickhouse对于压缩块的处理有关。第三章已经提过,clickhouse按照每8192行生成一个block。但如果8192行的数据依然很小怎么办?例如UInt8类型,一行数据只有8位1字节。即使8192行数据也仅仅只有8192Byte=8KB。这个数据量用来压缩还是显得太小。因此,clickhouse在处理时,会按照每个压缩块最小64KB,最大1M的规则进行处理。即一个block数据总和小于64K时,会继续取下一个block。因此会出现多个block出现在一个压缩块中。标记文件中的第三个参数就是用来处理这种情况的。
因此假设一个标记文件的内容如下:
| 0 | 0 | 0 |
| 1 | 0 | 8192 |
| 2 | 0 | 16384 |
| 1 | 12016 | 0 |
读取第2块block时,根据2*24Byte=48,定位到(2,0,16384)这一行,然后根据0,从bin文件中读取偏移量=0的数据块,经过解压缩后再根据16384读取解压缩后从16384开始的数据,即可找到对应的原始数据。
总结
clickhouse的索引由于其存储引擎的设计,可以做的非常简单。主要有一级索引和标记组成。一级索引实现数据到block的映射,标记实现block到文件偏移量的实现。另外,由于一级索引非常小,1亿条数据只需要1万多行的索引,因此一级索引可以常驻内存,加速查找。
同时,clickhouse还提供了二级索引,不过二级索引比较简单,且不是必须的,对整体性能影响也不大,因此我会在番外篇中介绍二级索引。
至此,clickhouse的存储引擎的设计已经更新完毕,下一期我将通过一个完整的例子串联起整个clickhouse的存储引擎的工作原理。并且对之前写得部分进行优化,尤其是增加大量的图片来向读者更清晰地介绍概念。
相信通过这几节的内容,大家对clickhouse的设计哲学也有了一定的认识。这边我又要提出一个新的疑问,读者可以事先思考一下:按照本文目前的介绍来看,clickhouse的加速强在设计上,那么为什么clickhouse要使用C++语言编写?使用JAVA能否实现同样的性能?为什么?这个问题将会引出下一部分的核心内容:clickhouse的计算引擎。让我们在下一部分重逢,开始一段更有挑战的旅程。